| Team manager: | Dr. Alexander P. Vazhenin |
| Position: | Senior Researcher |
| Department: | Supercomputer Software |
| Organization: |
Computing Center Siberian Division |
| Organization Address: |
6, Lavrentiev Ave. Novosibirsk, 630090 Russia |
| Phone: | (3832) 350994 |
| Facsimile: | (3832) 357942 or (3832) 324259 |
| E-mail: | vazhenin@ssd.sscc.ru |
The goal of this work is to design software tools supporting Superprecision Parallel ARiTHmetic computations (SPARTH) in modern supercomputers, to estimate the possibilities of these systems, and to develop the high-accuracy parallel algorithms for solving some applied problems.
The goal of this work is to develop software tools supporting Superprecision Parallel ARiTHmetic computations (SPARTH) in modern supercomputers and to estimate the possibilities of these systems. The main directions of these investigations are:
Note also, that the solution of applied problems will be implement by the following stages:
Therefore, the SPARTH-library have to support mixed computations using both the traditional data representation and special SPARTH-numbers.

In the dynamic accuracy mode, the operand capacity may be altered in the interval defined by the user. The number of available vector registers is formed according to the maximum ordered capacity value. Computations may be started with relatively small capacity of operands. If needed,the SPARTH-processor may be switched to a next capacity limit by means of precision control procedures.
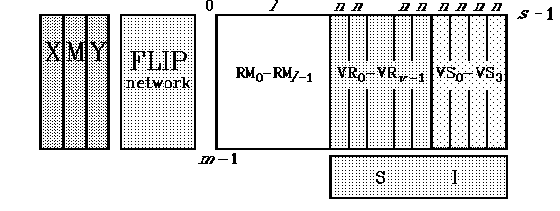
In the SPARTH-processor three types of data are used:
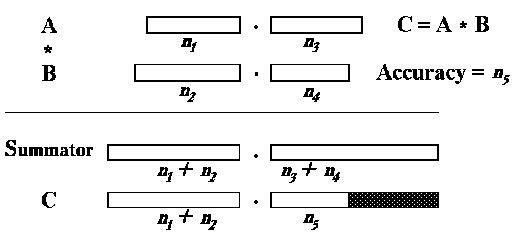
Processor instructions provide effective interaction of its subsystems and execution of high-precision parallel computations. Arithmetic operations are executed in two stages. At first, the exact result (without rounding) is formed in HPS, then it is stored into destination registers using the rounding operations for multiplication and division. In the dynamic accuracy mode, the data located in HPS may be stored without rounding. The peculiarity of the library implementation is that it is reduced to few basic operations, which execute structural transformations of vectors, and special types of computations. This allows effective mapping of algorithms on VPS-architecture.
The other example is a SPARTH-library, which is an extension of C-language. It supports the programming of computations with dynamically changed length of operands in MIMD-systems based on Message Passing Interface (MPI). Some implemented experiments show that this library can be considered as the portable program package.
As shown in Figure, each number has three parts. We call two of them standard parts (sign and std_int, std_frac). These parts are created only when the number is initialized. They represent solid memory blocks. Doing this, we attempt to reduce fragments of the memory and number of Operation System requests for open/close operations.

Dynamic change of operand length is realized by producing additional, so called non-standard parts which combined to one-joined structure. Every block of this type has the area of information, and the pointer to the next block (point_int and point_frac). The number of non-standard blocks is kept in the special poles.
NOTE
The non-standard integer part will not be reduced. We allow to increase the absolute number value as high as it is possible in the system. There is no overflow in a library.
The SPARTH-libraries contain also a set of standard procedures implementing the following operations:
SPARTH-SIMD library was realized on the associative array processor ES-2720, the architecture of which is similar to STARAN, and has the following characteristics: the PEs number of m=256, the size of local memory in each processing channel of s=4096. This approach can be used as well for other fine-grained SIMD-systems (DAP, MPP, CM-1, CM-2, etc.).
At first, SPARTH-MIMD library was produced for a multitransputer system containing five processors T800/20. This library was ported also to the PowerX'Plorer system of Parsytec including the Sun-5 workstation as a host and 8 computing nodes. Each nodes consists of the T805 transputer and PowerPC-601 processor. The sequential high-accuracy algorithms were investigated on the IBM PC/486 and Pentium computers, and the pipeline processor of INTEL/860. This confirms that it can be considered as a portable programming system.
LINEAR ALGEBRA PROBLEMS
Linear Algebra is a basis for solving many applied problems. A list of some high-accuracy parallel algorithms was shown above. The future investigations are oriented to extend a set of these algorithms. We are going to develop the algorithms and programs for solving the following problems: eigenvalue problems; matrix inversion; Kholessky decomposition; sparse systems of linear equations.
MATHEMATICAL PHYSIC
The nonstationary problems of mathematical physic require to solve the large sparse systems of linear equations containing ill-conditioned matrices. Usually, the iterative methods are used for solving these systems. One such approach is the method of partial factorization combined with conjugate gradient method. This can allow the high speed of convergence of iterative process. We are going to investigate an impact of rounding errors on the solution time as well as to improve the final accuracy by increasing both the problem size and operand capacity.
VISUAL GEOMETRY AND TOPOLOGY
Recent achievements of visual geometry and topology made nontrivial mathematical concepts understable and applicable. In some cases the dynamically changed length of operand can support accurate intermediate computations. For example, the extraction of ridges and ravines of a surface is based on differential geometry of the surface. Calculations of many partial derivatives (up to fourth order) are essential to implement this procedure. Therefore, the standard data formats can be not good enough if the surface is very complex.
PARTICLE-IN-CELL METHOD and N-BODY PROBLEMS
Usually, the systems being investigated consist of many elements which interact with other through gravitational, magnetic or electric force. Its evolution can be calculated by integrating simultaneous differential equations for the large number of particles. In this case, the basic operations will be dot products or sums of large size. This requires very long operands to obtain the accurate result.