PSA properties
The following fundamental concepts form the background of the Parallel Substitution Algorithm.
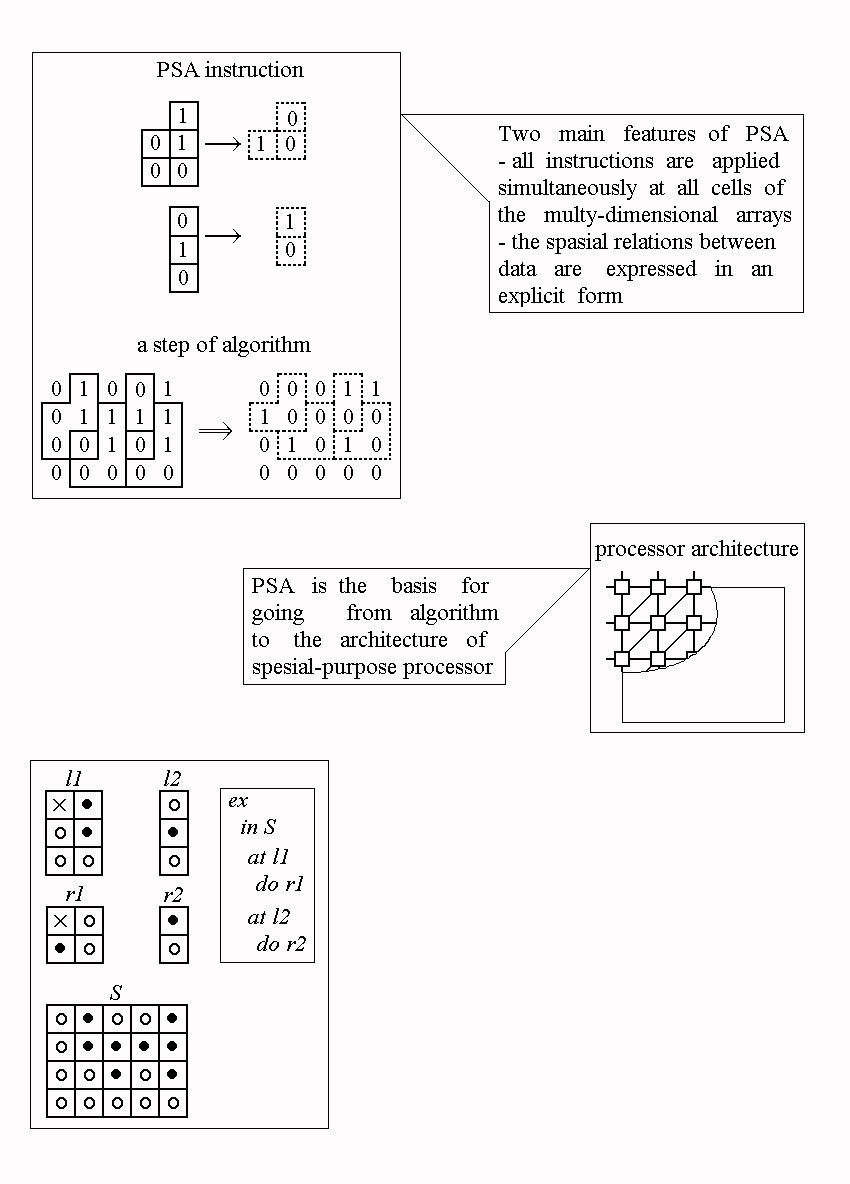
Fine-grained parallelism. Each data--item is introduced being attached to a point in the computation space represented as a countable discrete set of names. The computation is an iterative procedure over a data array in this space. At each step certain data subarrays are replaced by other ones, these actions being done all over the whole data--array.
Decentralized control. No order of operation execution is defined in the model. Each substitution is performed when and where the ready conditions coincide with a data--pattern in the space. Thus, the associative mechanism of the time--spatial control of the computation process is performed, the spatial relations being explicitly represented by means of the functions defined in the computational space.
Synchronous mode of execution. An abstract outer clock is presumed to exist, making the computational process to obey the following rules:
- all operations ready to be executed should be executed simultaneously with the first coming clock pulse,
- no changes in the array are allowed out of the clock pulses. The asynchronous mode of execution is also of great theoretical interest. Its investigation is very important for understanding the behavioral properties of computations in the cellular spaces.
Interpretability by automata nets. A set of substitutions representing the cellular computation admits the direct mapping onto a net of automata. This allows one to construct methods and tools for architectural design of hardware implementation of cellular algorithms.
The direction of the development of the PSA theory is stipulated by the objective of its creation: to constitute the fundamentals for methods of synthesis of algorithm--oriented architectures of cellular processors.
Equivalent Transformations of PSAs
2D -> 3D PSA Transformation
The implementation of optical data processing is expected to give a qualitative shift in the connections problem solution. The most efficient solution is in using some kind of multiplanar structure organized as follows. Inside the layers the connections are made with metallized strips like those in solid--state chips.
Between the layers the switching elements are connected by light
signals. The whole length of connections is reduced firstly due to
the cellular architecture and, secondly, due to the transfer of a
great deal of connections to the third dimension.

Three methods have been elaborated:
Coarse-Grained Stratification is to partition the set of parallel substitutions into several subsets, each subset being put into correspondence to a layer of the 3D naming set.
Fine-Grained Stratification is the method of 2D -> 3D transformation when each substitution is stratified apart being decomposed into a set of more simple ones corresponding to one or several components of left--hand side and right--hand side configurations.
Computation Space Reshaping results in stratification in which the template pattern becomes stretched along the third axis.
Synchronous-Asynchronous Transformation of PSAs
- What are the features a parallel substitution set (PSS) is to possess in order to meet validity conditions.
- How to transform the PSS of a given PSA into an equivalent PSS which meets the validity conditions.
- What price in hardware and in execution time is to be paid for the abandonment of synchronizing clock.
A method of constructing a PSS, such that the asynchronous mode of its execution simulates a given PSA is presented. The method is based on the concepts of behavioral properties and validity conditions.
Space--Time Transformation of PSAs
A procedure is created which transforms a PSA, intended to process an r--dimensional cellular array into a result equivalent PSA, which deals with a (r-1)--dimensional cellular array. Obviously, the time needed for obtaining the result increases.
The proposed procedure is shown to be effective (in the sense that it results in a PSA), if the initial PSA meets certain conditions, which are proved to be necessary and sufficient. These conditions are based on the PSS validity properties for the asynchronous mode of computation.
Computer Tools for Simulating a Cellular Computation
ALT has a multiwindow interface. It includes tools for editing the textual and graphical forms and a translator from a special high-level language which uses C-language as a prototype, into the interior representation, as well as a number of tools for displaying the parameters of computation process under simulation.
Such a system have been urgently needed for experimenting with fine-grained parallel algorithms and watching distributed computation processes.
Of even greater importance is the possibility to improve and modify a PSA according to the technical requirements when performing the architectural design of a cellular processor.
The main peculiarity of ALT is the independence of the program representation of the three following things used:
- the graphical objects, representing cellular arrays and configurations,
- the PSA execution program,
- the procedures for computing values of functions when functional PSA are simulated.