In such a way, each linear algorithm is characterised by such an integer positive constant m that an operation ai may interact only with the operation aj, aj inŽ{ai-m, ...,ai+m}. Therefore, if an algorithm is being mapped on the line of PEs (a linearly ordered set of PEs, each processor PEi is connected with PEi-1 and PEi+1. This is minimal connections to successfully execute a linear algorithm) the operations of neighbourhood will be assigned on the processors, after that all interactions of ai- operation can be performed. A similar program can be assembled out of operations. Especially developed assembly parallel programming language and system INYA [14] support the implementation of linear algorithms.
2.2 Assembly Technology
This is a unified technology of problem parallelization and development of parallel programs for MIMD multicomputers. Contrary to partitioning a program is assembled out of the ready-made fragments (code + data) keeping the "seams" of assembling. The whole assembled problem may be divided (parallelized) into the parts only along these "seams". Certainly, each part should be executable at least on one PE of multicomputer. Parallel programming system INYA [14] supports the assemble style of programming.
3 Linearization of the PIC Method
We believe that many mass algorithms can be linearized and implemented in the assembly technology. Our main efforts were applied to linearize algorithms of the PIC.
3.1 Concept of the PIC
The main idea of the PIC method is considered from the viewpoint of computation structure. The physical aspects are not considered at all. A more detailed description of the PIC method can be found in [15,16].
Plasma is represented as a large number of particles. Each particle is represented by its co-ordinates, velocity and mass/charge.
The real physical space is represented as 3-D box, a model of physical space (space of modelling). The whole space of modelling is divided by the rectangular grid into cells upon which the electrical E and magnetic B fields, current density U and charge density P are discretized. In the assembly technology the space of modelling is assembled out of small boxes (cells), fig. 1.
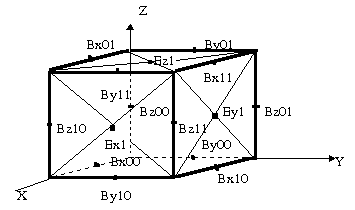
Thus, each cell contains the description of electrical E and magnetic B fields affecting inside the cell, fig. 2. The values of electrical and magnetic forces at any point inside the cell are calculated by interpolation. The more number of cells the more precision of electrical and magnetic fields representation.
Electrical E and magnetic B forces of space affect the particles located inside the cell changing their velocities and co-ordinates.
On the other hand each particle affects values of electrical and magnetic fields at nearest grid points since it changes the current density U and charge density P at these points.

|
|
| Fig. 1 | Fig. 2 |
Dynamics of the system is attained by integrating the motion equations of each of the particle at a series of discrete time steps. At each odd step new values of velocity and co-ordinate of all the particles are calculated from the values of electromagnetic fields.
After all the particles have been moved to their new co-ordinates the values of electrical E and magnetic B fields inside the space of modelling should be recalculated because the current density U and the charge density P at the grid points have been changed. Only the values of electrical and magnetic fields inside the cell and its adjacent cells are involved in computations. These calculations constitute the even steps of modelling. Odd and even steps are loop wise repeated calculating the tracks of the particles. The process of modelling is terminated from physical reasons.
3.2 Problems of Parallel Implementation
The main problem of programming is that the control structure of a parallel program and data distribution among PEs depend not only on the volume of data, but on the data structure as well. With the same volume of data but with the different particles distribution inside the space the program should be organised in a different way. The law of particles distribution is defined by the initial conditions of a physical experiment and is not defined by the system of equations that describes a specific physical problem.
Let us consider some examples of particles distribution. The particles distributions below correspond to the different real physical experiments.
- Uniform distribution of the particles. This is the case of the plasma cloud modelling.
- The space modelling has n1 x n2 x n3 size. The particles are uniformly distributed in k x n2 x n3 size space (k much less than n1) - the case of plate.
- Flow. The set of particles is divided into two subsets: the particles with zero initial velocity and active particles with the initially nonzero velocity. Active particles are organised as a flow crossing the space along a certain direction.
- Explosion. All the active particles are initially concentrated inside a cell.
Workload of PE mainly depends on the number of processed particles. For their processing PE should contain as cells as particles located inside them. In such a way, for different particles distributions different methods of parallelization should be applied and the programs of different control structures should be generated. Review of different methods of the PIC implementation can be found in [17].
Another problem of parallel implementation of the PIC method is that the particles distribution is not stable during modelling. In particular, the uniformly distributed particles might be concentrated inside a single cell in several steps of modelling. In such a way, the control structure of a parallel program and data distribution among PEs should be dynamically changed during the computation.
3.3 Linearized version of PIC
First, the atomic fragments of computation are defined. Such fragments are the cells, each cell description containing all the variables to keep the values of all the forces, description of particles inside of it and all the computations: procedures to recalculate the particles co-ordinates, new values of fields, etc. The description of particles which are moved into a certain cell during modelling is added to this cell dynamically. Computations inside the cells are defined as a noninterpreted scheme [18].
At the second step the space of modelling (fig. 1) is assembled out of cells as a wall is laid out of bricks. The cells are included into the space of modelling together with all the computations defined inside the cells.
The seams of assembling (the lines in fig.1) define all the permissible divisions of the problem (its parallelization) into parts. The seams of the PIC assembling permit us to divide the space of modelling along the attached cells, in particular, into layers. In so doing both the code and data are partitioned .
The computation, defined inside the cell, consumes a few resources (PE memory and PE time) and it is possible to compose a suitable volume of computation (a suitable number of cells) out of these cells for each PE abiding by the general algorithm of PIC parallelization.
Assembling of the PIC provides the universal way of dynamic PE loading. If a PE is overloaded, then some cells processed on this PE should "fly" to a certain (neighbouring) less loaded PE. Obviously, they should "fly" with all the variables defining all the fields and the particles inside and the computations inside as well. For the case of explosion, where all the active particles are concentrated inside a single cell, the method of virtual cells is applied.
For our implementation of the PIC a layer was chosen as an atomic fragment. One or more adjacent layers constitute a block. The space of modelling is divided into several blocks that are assigned to specific PEs for processing. The number of layers of each block is chosen in such a way to provide an equal workload for every PE. If the PIC should be processed on the line of n PEs, the space of modelling is divided into n blocks (fig. 3). In the case of the workload imbalance of a certain PE, a suitable layer (code + data, including particles inside) should "fly" to a neighbouring PE (rebalancing procedure).
Dynamic load balancing can be done in many different ways using as centralised as decentralised algorithms. We have used a centralised algorithm. The idea is in the following. The workload of PE depends proportionally on number of processed particles. In such a way if N particles are to be processed on n PEs, then a normally loaded PE should process N/n particles. If imbalance of at least one PE occurs in the coarse of modelling, this PE is able to recognise it at the moment when the number of particles substantially exceeds N/n. Then this PE initiates rebalancing procedure. At request of this PE, one of the PEs, assigned in advance, requires from the other PEs the number of particles processed by them and broadcasts this information to all the PEs. Each PE schedules the layers transfer between PEs and accomplishes its own part of this schedule.
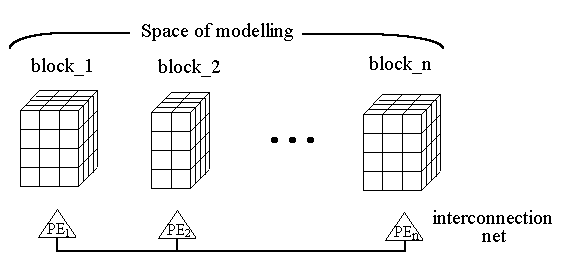
Fig. 3
3.4 Mapping of linearized PIC onto 2D grid
Linearized PIC is suitable to be executed on 2-D grid of PEs. To provide it, mapping of linearized PIC onto 2-D grid should be constructed. It may be done as follows.
Let l x m 2-D grid of processor elements be given. Block_i is assigned for processing on the i-th row of 2-D grid, 0 < i < l+1. Block_i is formed in such a way to provide an equal workload of every row of the processor grid. Certainly, this is a linear algorithm too. Then, block_i is divided into m sub-blocks block_ij (fig.4), j=1,...,m, which are distributed for processing among m PEs of the row. Block_ij is composed in such a way to provide an equal workload of every PE of the i-th row.

Fig. 4
3.5 Mapping of 2D grid onto hypercube
A hypercube interconnection net is suitable to execute the linearized PIC too. Mapping of the linearized PIC to a hypercube can be constructed as follows.
Denote n-hypercube nodes as ai1,i2,...,in, ik={1,-1}, 0 < k < n+1. Each node ai1,i2,...,in is connected with n other nodes whose indexes are different from i1,i2,...,in by one position, in other words, whose indexes look as i1,..., -ik,....,in for some k, 0 < k < n+1.
Let us need 2l x 2m grid, l+m=n. The correspondence between hypercube and grid nodes is done as follows:

Hence, the numbers of hypercube nodes of any row have the same values of the first l indexes as the node numbers of any column have the same values of the last m indexes. Note, that the number of any grid node differs from the numbers of the neighbouring grid nodes only in one index, therefore, there is a link between these nodes in the hypercube. In such a way, a part of hypercube links is even unnecessary for the PIC implementation.
4 Implementation of the Linearized PIC
Using the experience gained and the ideas of assembling and linearizing we have implemented the PIC for Parsytec PowerXplorer with 8 processor nodes. Each node consists of PowerPC 601 (80Mhz, 8Mb) and SGS Thomson T805 transputer (1Mb). Sun SPARC station 5 (70Mhz, 32Mb) is used as a host. The interconnection network transfer performance is 8.8 MB/sec.
Parallel programming system PARIX is a standard parallel software environment of PowerXplorer. One of the features of PARIX is high degree of hardware abstraction via virtual links, topologies and virtual processors. Actually, 2D grid is a physical network topology of PowerXplorer. Since the PIC is linearized (3.3) we need only the line or 2D grid physical topologies. So, an atomic fragment of this PIC implementation is a layer. A block of the adjacent layers is processed on each PE. Therefore, if the adjacent layers are processed on the same PE or on the neighboring PEs, there are physical links connecting these PEs. The time interval of modeling has been chosen in such a way that any particle is able to fly to the neighboring cell only during one step of modeling. In the case of the workload imbalance some layers are moved from overloaded PEs to the neighboring PEs.
Usually the number of layers is far greater than the number of PEs. Therefore, it is
possible initially to compose a suitable volume of computations out of these layers for
each PE. However, all particles might be concentrated inside one layer in the course of
modeling. Taking a column as an atomic fragment may partly solve this problem; but
it is not a fail-safe solution because the particles might be concentrated inside one cell
only. Thus, we are forced to introduce the notion of a virtual layer (column). A
fragment is duplicated in some adjacent PEs and particles of this fragment are
distributed among these PEs. However, in this case
903,168 particles of background were distributed uniformly. The other 96832 particles, representing the cloud, were placed in the centre of the space of modelling, its radius was far less than the size of a cell. As the grid consists of even number of layers, the cloud particles were concentrated into two adjacent layers. Therefore, initially all the PEs had more or less equal workload.
Total processing time is the sum of calculation time Tc, communication time Te, rebalancing time Tb and the time of data transfer to hard disk Td (the data are transferred to hard disk in order to visualise the process of modelling). The calculation time Tc is inversely proportional to the number of PE (while the number of layers is far greater than the number of PEs; it is true in this case). Communication time Te is a constant while the number of PEs is greater than 2, because the communications between adjacent PEs only are needed. All these communications are accomplished in parallel. If the number of PEs is equal to 4 (8), then the ration Tc/Te is equal to 8 (4) correspondingly. Rebalancing procedure consumed usually the different time from 1/3 to 1/2 of one time step of modelling depending on the particles number. Rebalancing time Tb may be ignored because rebalancing procedure was initiated about 5 times only for each program execution. The number of steps of modelling were greater than 200.
Let us consider another test with 24—x 24—x 36 grid and 200,000 particles (165,888 background particles and 34,112 cloud particles).
The program was executed on the line of 8 PEs. The behaviour of the program is characterised:
number of modelling steps - 300
about 25000 particles are processed on each PE
total processing time - 13.1 minutes
calculation time -10.8 minutes
communication time - 0.9 minutes
total rebalancing time - 0.1 minutes
number of rebalancing - 5
(rebalancing procedure is initiated if at least one PE has more than 25000*1.1 or less than 25000*0.9 particles)
The rest time is spent for data and processes loading.
The total execution time of the program with the same data on one PE is 80 minutes. So, the speed-up on 8 PE is equal to 6.
The program is suitable to be executed on different multicomputers. In particular, it was installed on MBC-100 during one hour only. The results of its testing were identical to results above.
5 Conclusion
Our next step to improve the PIC implementation is to develop its interactive visualisation. It should provide the visualisation of the course of numerical experiment and its control by changing a visual image of plasma cloud.
References
- [1] V.Malyshkin. Organization of Parallel Computation on Large-Block Hierarchical Multicomputer Systems. Programmirovanie, N.4, Moscow,1991.
- [2] A.Zabrodin, V.Levin, V.Korneev. The Massively Parallel Computer System MBC-100. In Proceedings of PaCT-95 (Parallel Computing Technologies) Int. conference, St.- Petersburg, Russia, 1995. LNCS, Vol. 964, Springer Verlag, pp.341-355.
- [3] Walker D.W. Characterising the parallel performance of a large-scale, particle-in-cell plasma simulation code// Concurrency: Practice and Experience. - 1990. - Vol.2(4), pp.257-288.
- [4] Campbell P.M., Carmona E.A., Walker D.W. Hierarchical domain decomposition with unitary load balancing for electromagnetic particle-in-cell codes// IEEE Computer Society. - 1990. - pp.941-950.
- [5] Walker D.W. The hierarchical spatial decomposition of three-dimensional particle-in-cell plasma simulations on MIMD distributed memory multiprocessors// Report ORNL/TM- 12071, U.S. Department of energy, Engineering Physics and Mathematical Division, Mathematical Sc. Section.
- [6] Sturtevant J.E., Campbell P.M., Maccabe A.B. Performance of a particle-in-cell plasma simulation code on the BBN TC2000// Concurrency: Practice and Experience. - 1992. - Vol.4(1), pp.1-18.
- [7] D. Walker Particle-In-Cell Plasma Simulation Codes on the Connection Machine// Computer System in Engineering, 1991, Vol. 2, N 2/3, pp. 307-319.
- [8] I. Foster, D. Walker Paradigms and Strategies for Scientific Computing on Distributed Memory Concurrent Computers// In Proceedings of the High Performance Computing 1994 Conference, La Jolla, CA, April 11-15, 1994. Society for Computer Simulation, San Diego, CA.
- [9] D. Walker The Implementation of a Three-Dimensional PIC Code on a Hypercube Concurrent Processor. Proceedings of the Fourth Conference on Hypercubes, Concurrent Computers and Applications, Ed. By J.Gustafson, March 6-8, 1989, Monterey, CA. pp. 1255-1261
- [10] T. Hoshino, R. Hiromoto, S. Sekiguchi, S. Majama Mapping schemes of the Particle-In- Cell Method Implemented on the PAX Computer// Parallel Computing, 1988/89, N 9. pp. 53-75.
- [11] O. Lubeck, V. Faber Modeling the Performance of Hypercubes: A Case Study Using the Particle-In-Cell Application// Parallel Computing, 1988/89, N 9. pp. 37-52.
- [12] V.E.Malyshkin. Linearized mass computation, in Proceedings of Parallel Computing Technologies International Conference (1991) Novosibirsk, pp.339-353. World Scientific, Singapore.
- [13] V.Malyshkin. Functionality in ASSY System and Language of Functional Programming. - In Proceedings of the First International Symposium on Parallel Algorithms/Architectures Synthesis. 1995, Aizu, Japan. IEEE Comp. Soc. Press, Los Alamitos, California, pp. 92-97.
- [14] V.A. Anisimov, V.E.Malyshkin. Assemble Parallel Programming System INYA, in Proceedings of Parallel Computing Technologies International Conference (1991) Novosibirsk, pp. 339-353.
- [15] Hockney R.W., Eastwood J.W.// Computer Simulation Using Particles. McGraw-Hill Inc. 1981
- [16] Berezin Yu.A., Vshivkov V.A. The method of particles in rarefied plasma dynamic. - Novosibirsk: Nauka, 1980 (in Russian).
- [17] Vshivkov V.A., Kraeva M.A.., Malyshkin V.E.. Parallel Implementations of PIC Method// Programmirovanie, N 2, 1997 (in Russian, to be published).
- [18] V.Valkovskii, V.Malyshkin. Parallel Program Synthesis on the basis of Computational Models. Nauka, Novosibirsk, 1988 (in Russian).
This page last updated on April 21, 1997 by Marina Kraeva.